数据结构 Graph
转载自 数据结构:图(Graph) 参考资料 大话数据结构 参考资料 数据结构和算法系列17 图
图是什么
一个图可以表示一个社交网络,每一个人就是一个顶点,互相认识的人之间通过边联系。
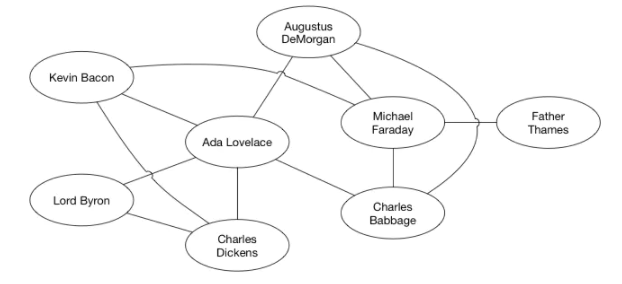
在图形结构中,节点之间的关系是任意的,图中任意两个数据元素之间都有可能相关。图 G 由两个集合 V(顶点 Vertex)和 E(边 Edge)组成,定义为
无向图
对于一个图,若每条边都是没有方向的,则称该图为无向图。图示如下:
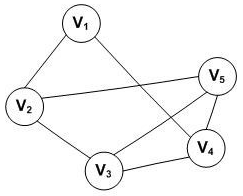
因此, 和 表示的是同一条边。注意,无向图是用小括号,而下面介绍的有向图是用尖括号
无向图的顶点集和边集分别表示为:
有向图
对于一个图G,若每条边都是有方向的,则称该图为有向图。图示如下:

因此, 和 是两条不同的有向边。注意,有向边又称为弧
有向图的顶点集和边集分别表示为:
注意:两边都有方向的叫做完全无向图
边的权重
边可以有权重(weight),即每一条边会被分配一个正数或者负数值。考虑一个代表航线的图。各个城市就是顶点,航线就是边。那么边的权重可以是飞行时间,或者机票价格。
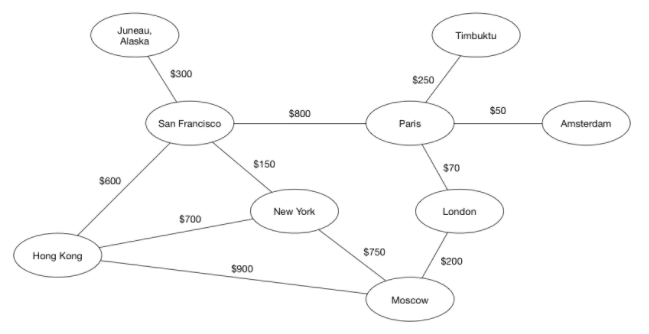
有了这样一张假设的航线图。从旧金山到莫斯科最便宜的路线是到纽约转机。
边的方向
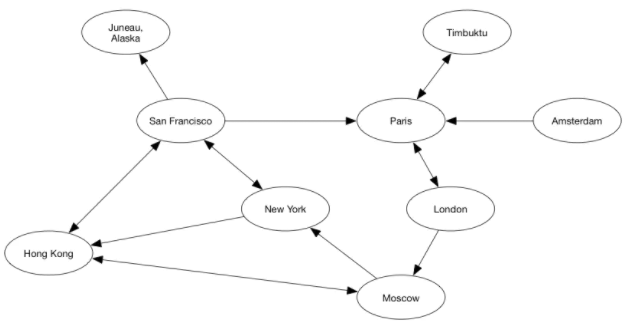
边可以是有方向的。在上面提到的例子中,边是没有方向的。例如,如果 Ada 认识 Charles,那么 Charles 也就认识 Ada。相反,有方向的边意味着是单方面的关系。一条从顶点 X 到 顶点 Y 的边是将 X 联向 Y,不是将 Y 联向 X。
继续前面航班的例子,从旧金山到阿拉斯加的朱诺有向边意味着从旧金山到朱诺有航班,但是从朱诺到旧金山没有(我假设那样意味着你需要走回去)。
下面的两种情况也是属于图:
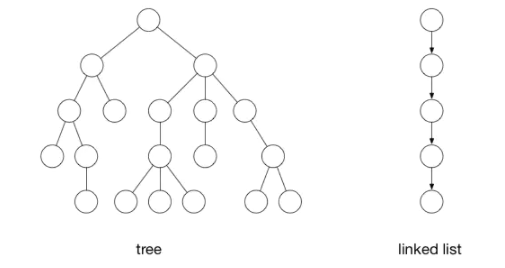
左边的是树,右边的是链表。他们都可以被当成是树,只不过是一种更简单的形式。他们都有顶点(节点)和边(连接)。
第一种图包含圈(cycles),即你可以从一个顶点出发,沿着一条路劲最终会回到最初的顶点。树是不包含圈的图。
另一种常见的图类型是单向图或者 DAG:
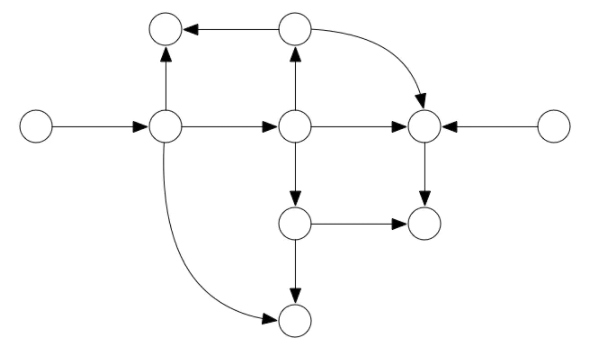
就像树一样,这个图没有任何圈(无论你从哪一个节点出发,你都无法回到最初的节点),但是这个图有有向边(通过一个箭头表示,这里的箭头不表示继承关系)。
为什么要使用图?
如果你有一个编程问题可以通过顶点和边表示出来,那么你就可以将你的问题用图画出来,然后使用著名的图算法(比如广度优先搜索 或者 深度优先搜索)来找到解决方案。
例如,假设你有一系列任务需要完成,但是有的任务必须等待其他任务完成后才可以开始。你可以通过非循环有向图来建立模型:

每一个顶点代表一个任务。两个任务之间的边表示目的任务必须等到源任务完成后才可以开始。比如,在任务B 和任务D 都完成之前,任务C 不可以开始。在任务A 完成之前,任务B 和 D 都不能开始。
现在这个问题就通过图描述清楚了,你可以使用深度优先搜索算法来执行执行拓扑排序。这样就可以将所有的任务排入最优的执行顺序,保证等待任务完成的时间最小化。(这里可能的顺序之一是:A, B, D, E, C, F, G, H, I, J, K)
程序员常用的另一个图就是状态机,这里的边描述了状态之间切换的条件。下面这个状态机描述了一个猫的状态:

顶点和边
理论上,图就是一堆顶点和边对象而已,但是怎么在代码中来描述呢?
有两种主要的方法:邻接列表和邻接矩阵。
邻接列表:在邻接列表实现中,每一个顶点会存储一个从它这里开始的边的列表。比如,如果顶点A 有一条边到B、C和D,那么A的列表中会有3条边
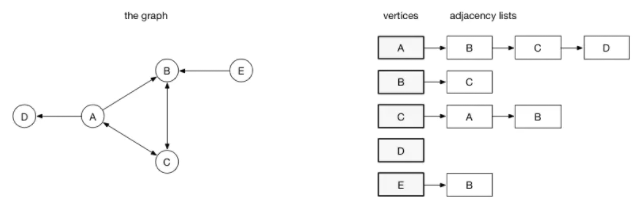
邻接列表只描述了指向外部的边。A 有一条边到B,但是B没有边到A,所以 A没有出现在B的邻接列表中。查找两个顶点之间的边或者权重会比较费时,因为遍历邻接列表直到找到为止。
邻接矩阵:在邻接矩阵实现中,由行和列都表示顶点,由两个顶点所决定的矩阵对应元素表示这里两个顶点是否相连、如果相连这个值表示的是相连边的权重。例如,如果从顶点A到顶点B有一条权重为 5.6 的边,那么矩阵中第A行第B列的位置的元素值应该是5.6:

往这个图中添加顶点的成本非常昂贵,因为新的矩阵结果必须重新按照新的行/列创建,然后将已有的数据复制到新的矩阵中。
所以使用哪一个呢?大多数时候,选择邻接列表是正确的。下面是两种实现方法更详细的比较。
假设 V 表示图中顶点的个数,E 表示边的个数。5
| 操作 | 邻接列表 | 邻接矩阵 |
|---|---|---|
| 存储空间 | O(V + E) | O(V^2) |
| 添加顶点 | O(1) | O(V^2) |
| 添加边 | O(1) | O(1) |
| 检查相邻性 | O(V) | O(1) |
“检查相邻性” 是指对于给定的顶点,尝试确定它是否是另一个顶点的邻居。在邻接列表中检查相邻性的时间复杂度是O(V),因为最坏的情况是一个顶点与每一个顶点都相连。
在 稀疏图的情况下,每一个顶点都只会和少数几个顶点相连,这种情况下相邻列表是最佳选择。如果这 个图比较密集,每一个顶点都和大多数其他顶点相连,那么相邻矩阵更合适。